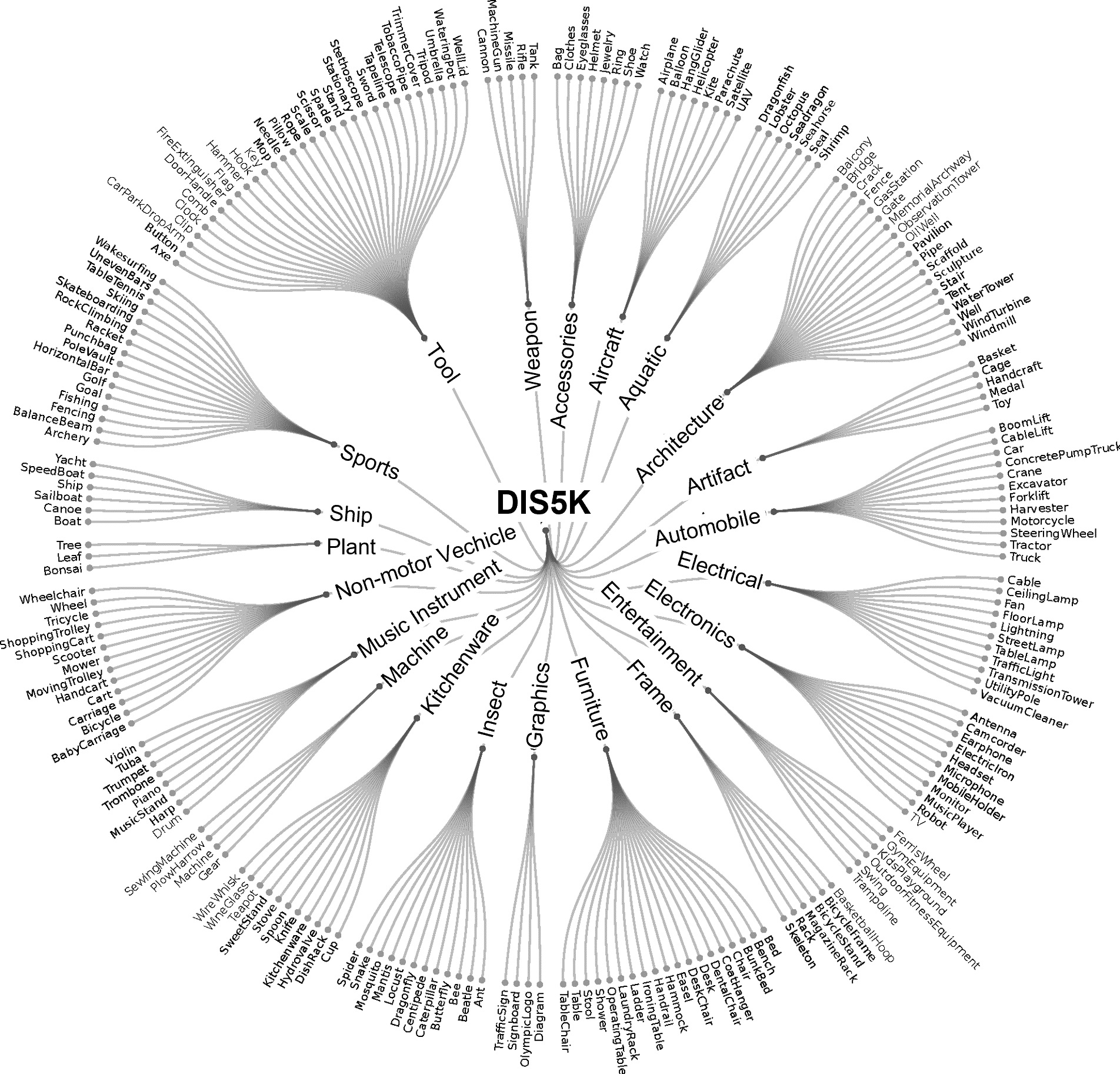
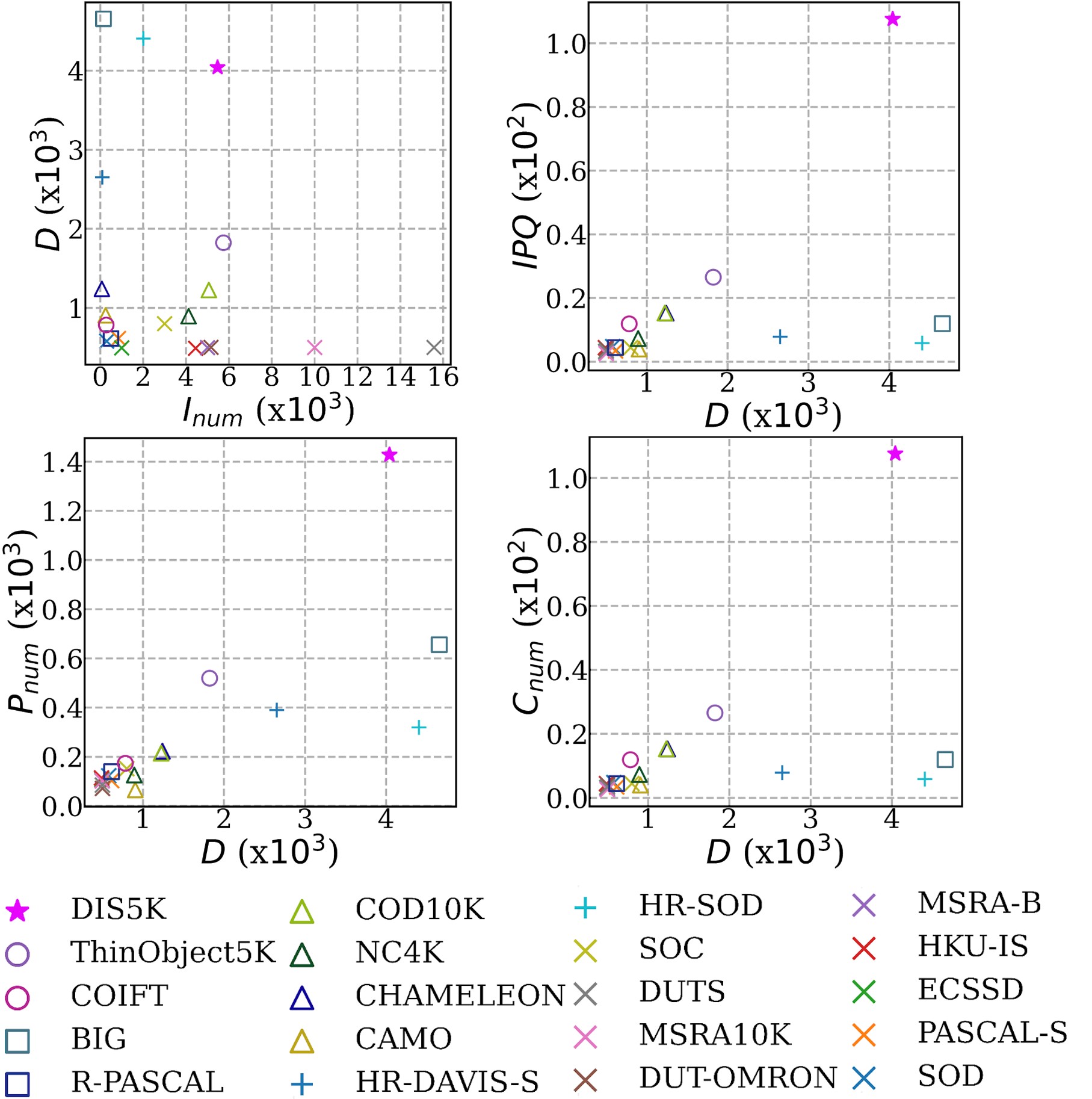
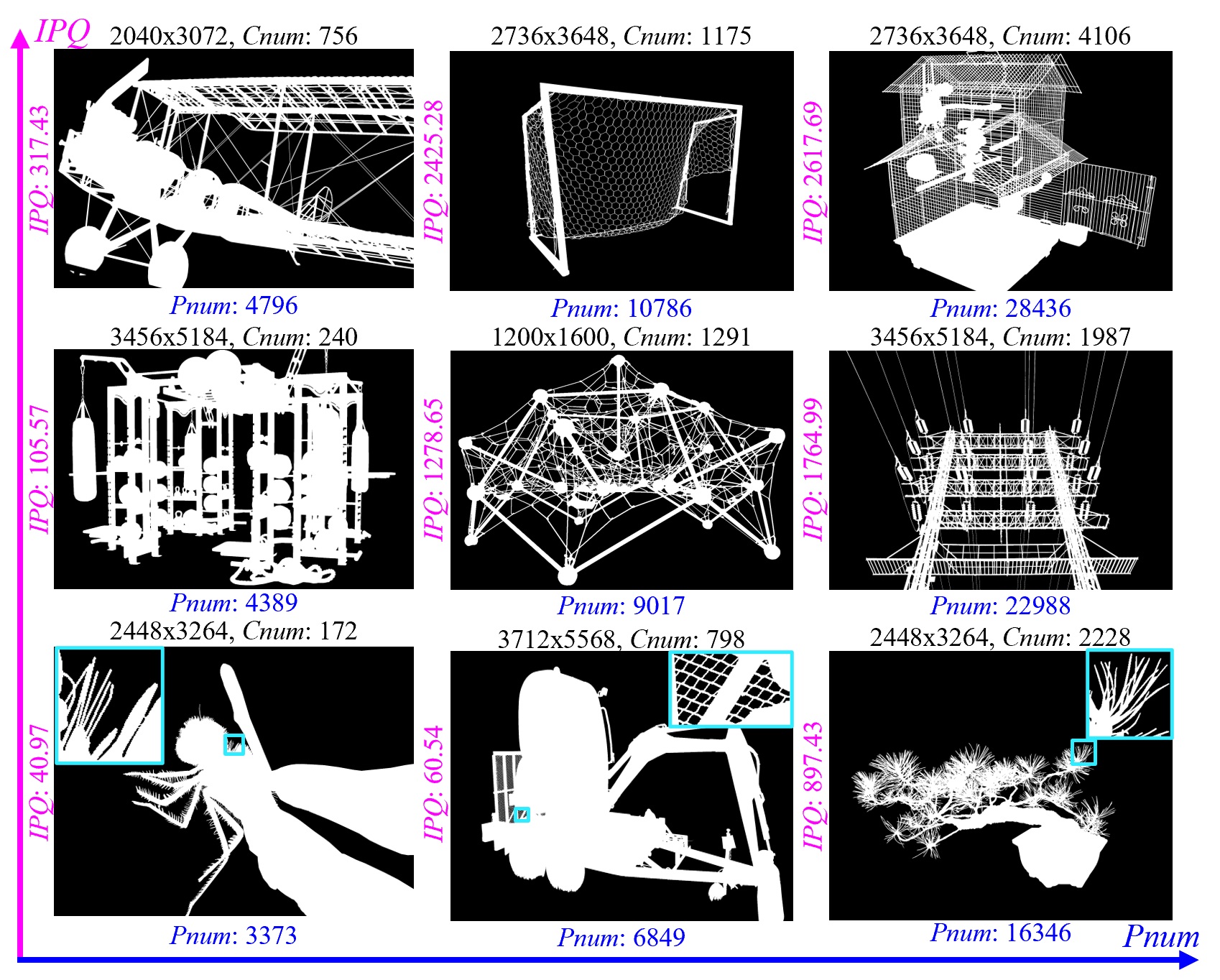
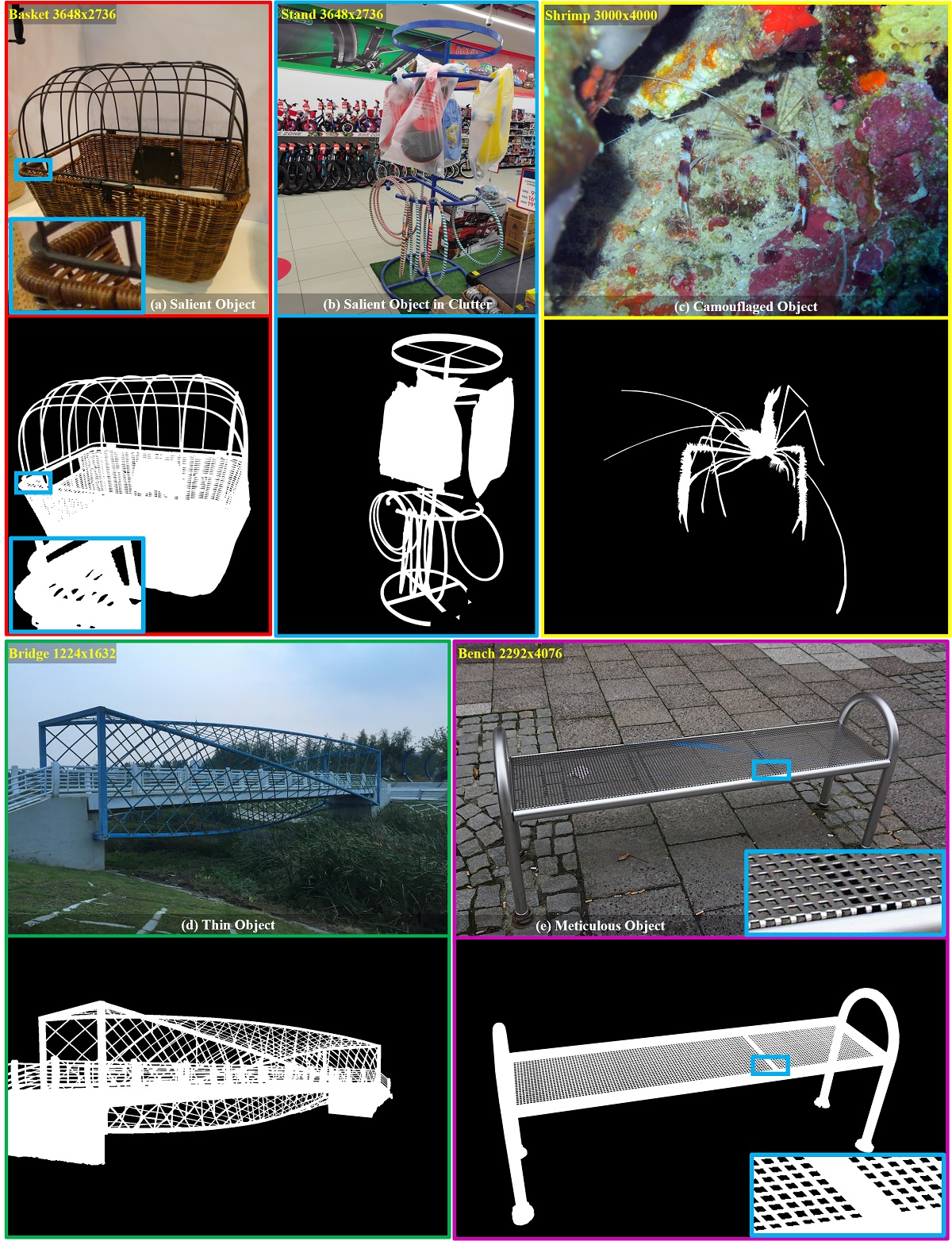
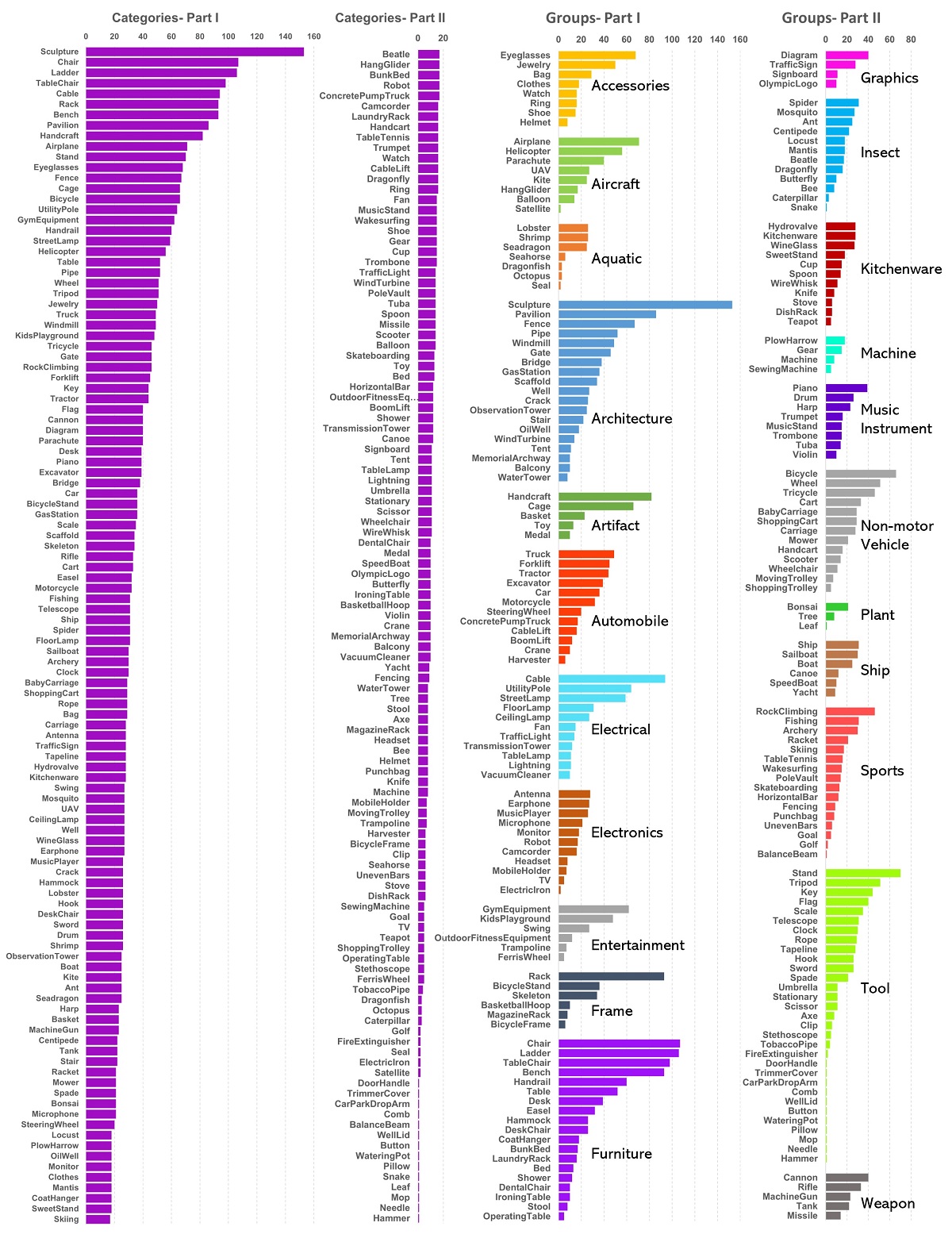
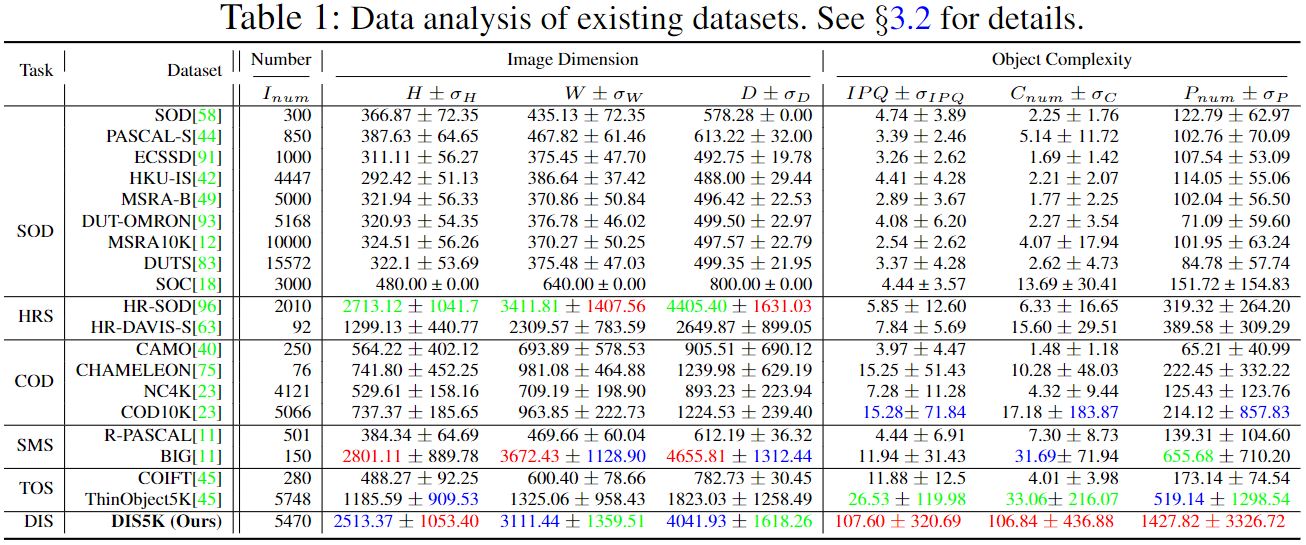
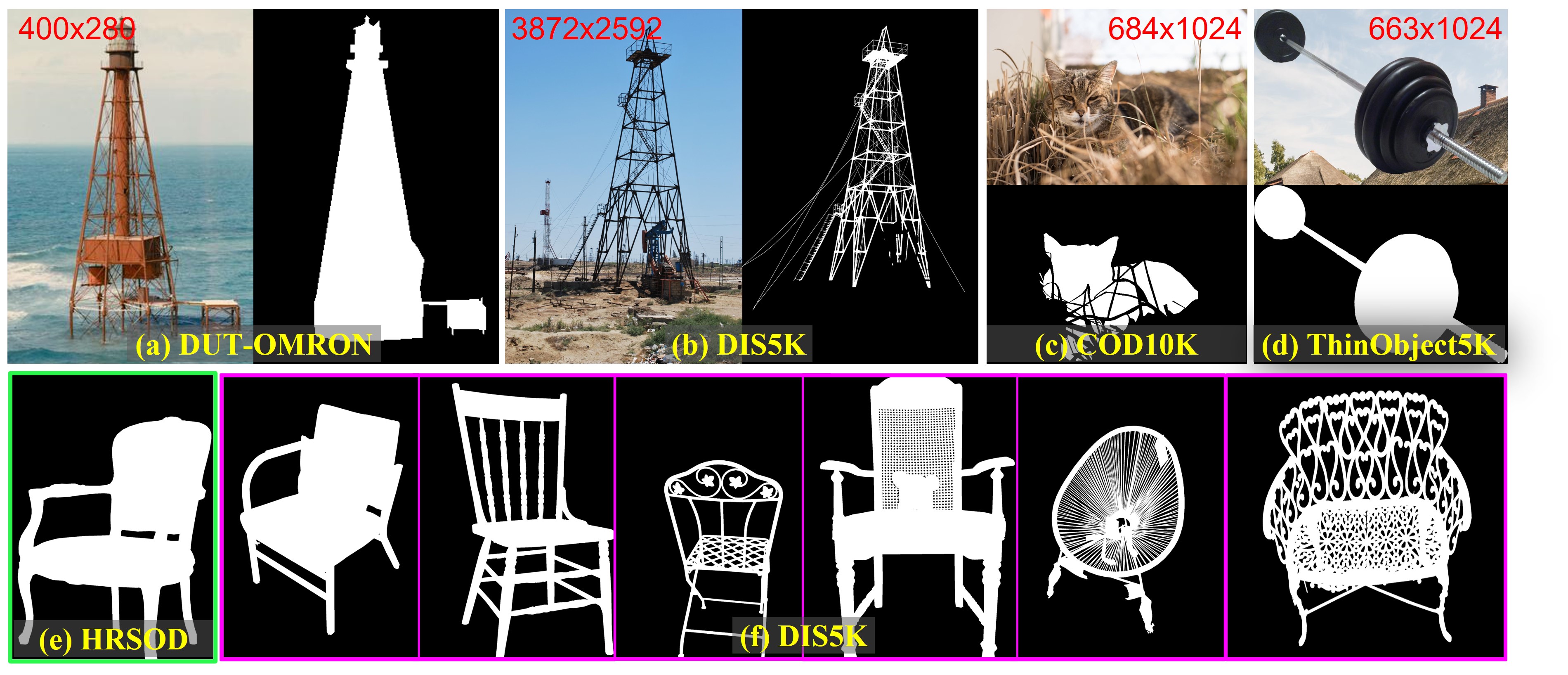
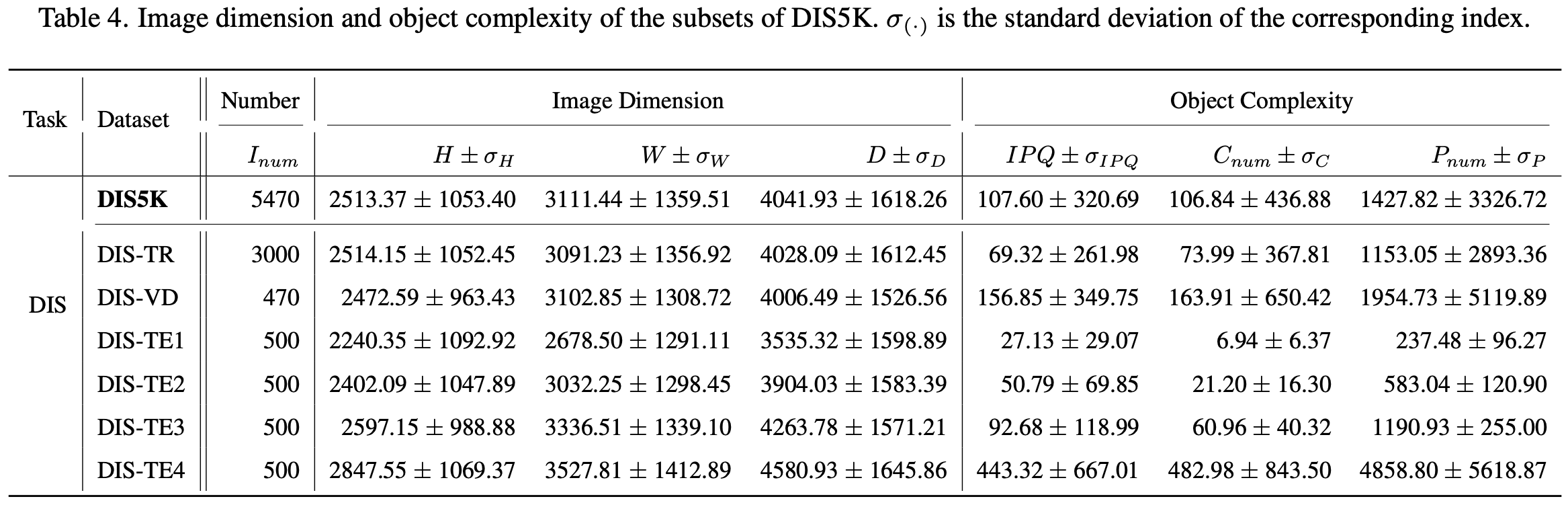
Demo

Image Background Removal

Art Design

Simulate View Motion
AR application based on images
AR application based on videos

3D Video Production